Реализация гауссовых моделей смеси с нуля: теория и практика
Введение в гауссовы модели смеси
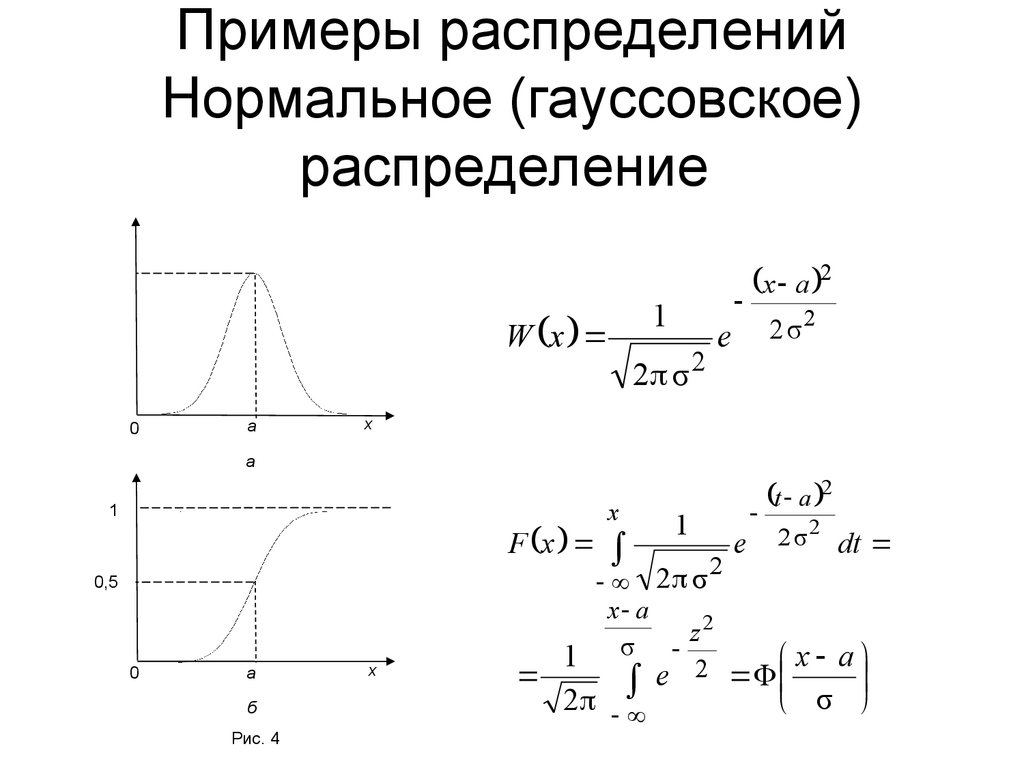
Гауссовы модели смеси (Gaussian Mixture Models, GMM) — это мощный вероятностный метод для решения задач кластеризации и оценки плотности распределения данных. GMM позволяют моделировать сложные многомодальные распределения с помощью взвешенной суммы гауссовых компонент.
Основная идея GMM заключается в том, что наблюдаемые данные порождаются смесью нескольких нормальных распределений с неизвестными параметрами. Задача состоит в том, чтобы по имеющейся выборке оценить параметры этих распределений и веса компонент смеси.
Формально модель GMM можно записать следующим образом:
p(x) = Σ(k=1 to K) π_k N(x | μ_k, Σ_k)
Где:
- K — число компонент (кластеров)
- π_k — веса компонент (π_k ≥ 0, Σπ_k = 1)
- N(x | μ_k, Σ_k) — многомерное нормальное распределение с параметрами μ_k (среднее) и Σ_k (ковариационная матрица)
GMM имеют ряд преимуществ по сравнению с другими методами кластеризации:

- Мягкая кластеризация — объект может принадлежать нескольким кластерам с разной вероятностью
- Гибкость в форме кластеров благодаря использованию ковариационных матриц
- Вероятностная интерпретация результатов
- Возможность оценки плотности распределения данных
Реализация GMM на Python
Рассмотрим пошаговую реализацию GMM с нуля на Python. Для начала импортируем необходимые библиотеки:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
Определим класс GMM:
class GMM: def __init__(self, n_components, max_iter=100, tol=1e-3): self.n_components = n_components self.max_iter = max_iter self.tol = tol def fit(self, X): # Инициализация параметров n_samples, n_features = X.shape self.weights = np.full(self.n_components, 1/self.n_components) self.means = np.random.randn(self.n_components, n_features) self.covs = np.array([np.eye(n_features) for _ in range(self.n_components)]) # EM алгоритм for iteration in range(self.max_iter): # E-шаг resp = self._e_step(X) # M-шаг self._m_step(X, resp) # Проверка сходимости if iteration >0 and np.abs(log_likelihood - prev_log_likelihood) < self.tol: break prev_log_likelihood = log_likelihood return self def _e_step(self, X): # Вычисление ответственностей resp = np.zeros((X.shape[0], self.n_components)) for k in range(self.n_components): resp[:, k] = self.weights[k] * multivariate_normal.pdf(X, self.means[k], self.covs[k]) resp /= resp.sum(axis=1, keepdims=True) return resp def _m_step(self, X, resp): # Обновление параметров N = resp.sum(axis=0) self.weights = N / X.shape[0] self.means = np.dot(resp.T, X) / N[:, np.newaxis] for k in range(self.n_components): diff = X - self.means[k] self.covs[k] = np.dot(resp[:, k] * diff.T, diff) / N[k] def predict(self, X): resp = self._e_step(X) return resp.argmax(axis=1)
Алгоритм EM для обучения GMM
Для оценки параметров GMM используется алгоритм максимизации ожидания (Expectation-Maximization, EM). Это итеративный алгоритм, состоящий из двух шагов:

E-шаг (Expectation)
На этом шаге вычисляются ответственности - вероятности принадлежности каждого объекта к каждому кластеру при текущих значениях параметров:
γ(z_nk) = p(z_k=1 | x_n) = π_k N(x_n | μ_k, Σ_k) / Σ(j=1 to K) π_j N(x_n | μ_j, Σ_j)
M-шаг (Maximization)
На этом шаге обновляются параметры модели, максимизирующие правдоподобие:
μ_k = Σ(n=1 to N) γ(z_nk) x_n / N_k
Σ_k = Σ(n=1 to N) γ(z_nk) (x_n - μ_k)(x_n - μ_k)^T / N_k
π_k = N_k / N
Где N_k = Σ(n=1 to N) γ(z_nk)
Алгоритм повторяется до сходимости или достижения максимального числа итераций.
Применение GMM для кластеризации
Рассмотрим пример применения реализованной модели GMM для кластеризации синтетических данных:
# Генерация синтетических данных
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=300, centers=3, cluster_std=0.5, random_state=0)
# Обучение модели
gmm = GMM(n_components=3)
gmm.fit(X)
# Предсказание кластеров
y_pred = gmm.predict(X)
# Визуализация результатов
plt.figure(figsize=(10, 5))
plt.subplot(121)
plt.scatter(X[:, 0], X[:, 1], c=y_true)
plt.title("Истинные кластеры")
plt.subplot(122)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("Предсказанные кластеры")
plt.show()
Этот код создаст синтетический набор данных с тремя кластерами, обучит на нем модель GMM и визуализирует результаты кластеризации в сравнении с истинными метками.

Сравнение с реализацией scikit-learn
Интересно сравнить нашу реализацию с готовой реализацией GMM из библиотеки scikit-learn:
from sklearn.mixture import GaussianMixture
# Обучение модели scikit-learn
gmm_sklearn = GaussianMixture(n_components=3, random_state=0)
gmm_sklearn.fit(X)
# Предсказание кластеров
y_pred_sklearn = gmm_sklearn.predict(X)
# Визуализация результатов
plt.figure(figsize=(15, 5))
plt.subplot(131)
plt.scatter(X[:, 0], X[:, 1], c=y_true)
plt.title("Истинные кластеры")
plt.subplot(132)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.title("Наша реализация")
plt.subplot(133)
plt.scatter(X[:, 0], X[:, 1], c=y_pred_sklearn)
plt.title("scikit-learn")
plt.show()
Этот код позволит сравнить результаты кластеризации нашей реализации GMM и реализации из scikit-learn.
Преимущества и недостатки GMM
Гауссовы модели смеси имеют ряд преимуществ:
- Гибкость в моделировании сложных распределений
- Вероятностная интерпретация результатов
- Возможность мягкой кластеризации
- Способность обнаруживать кластеры эллипсоидальной формы
- Масштабируемость на большие наборы данных
Однако у GMM есть и некоторые недостатки:
- Чувствительность к начальной инициализации параметров
- Необходимость задания числа компонент заранее
- Склонность к переобучению при большом числе компонент
- Сложность интерпретации результатов при большом числе признаков
Расширения и модификации GMM
Существует ряд расширений и модификаций базовой модели GMM, направленных на преодоление ее ограничений:
Байесовские GMM
Байесовский подход позволяет автоматически определять оптимальное число компонент с помощью априорных распределений на параметры модели.
Разреженные GMM
Использование регуляризации L1 позволяет получать разреженные решения, где часть весов компонент обнуляется.
GMM с общей ковариационной матрицей
Использование одной общей ковариационной матрицы для всех компонент позволяет уменьшить число параметров модели.
GMM с диагональными ковариационными матрицами
Использование диагональных ковариационных матриц упрощает модель и ускоряет вычисления.
Иерархические GMM
Построение иерархии моделей GMM позволяет моделировать сложные многоуровневые структуры в данных.
Практические рекомендации по применению GMM
При использовании GMM на практике полезно учитывать следующие рекомендации:
- Проводить предобработку данных (нормализация, удаление выбросов)
- Использовать несколько случайных инициализаций для выбора лучшей модели
- Применять кросс-валидацию для выбора оптимального числа компонент
- Анализировать веса компонент для выявления незначимых кластеров
- Визуализировать результаты для лучшего понимания структуры данных
- Комбинировать GMM с другими методами для повышения качества кластеризации
Заключение
Гауссовы модели смеси представляют собой мощный и гибкий инструмент для решения задач кластеризации и оценки плотности распределения. Реализация GMM с нуля позволяет лучше понять принципы работы алгоритма и его особенности.
Несмотря на наличие готовых реализаций в популярных библиотеках, понимание внутреннего устройства GMM важно для эффективного применения этого метода на практике и его дальнейшего развития.
Модели GMM находят широкое применение в различных областях, включая компьютерное зрение, обработку речи, биоинформатику и анализ финансовых данных. Дальнейшие исследования в этой области направлены на разработку более эффективных алгоритмов обучения, автоматический выбор числа компонент и интеграцию с глубокими нейронными сетями.